Join the Teckiy Community
Sign up for Free !!
World's first open source developer community with
Ticketing System

 0 reactions
0 reactions
Introduction
Caching is pivotal in ensuring swift data retrieval and enhancing application performance. SQLite, a lightweight database, combined with Redis, a high-speed in-memory cache, can immensely optimize the responsiveness of applications. Let’s delve into how to set this up.
In this example, we will treat SQLite as RDS , Lets install
1. Installation
pip install sqlite
2. Create and Populate Database
import sqlite3
# Connect to SQLite and create a new database file
conn = sqlite3.connect('example.db')
cursor = conn.cursor()
# Create a table and populate it
cursor.execute('''CREATE TABLE users (id INTEGER PRIMARY KEY, name TEXT)''')
cursor.execute("INSERT INTO users (name) VALUES ('Alice')")
cursor.execute("INSERT INTO users (name) VALUES ('Bob')")
conn.commit()
conn.close()

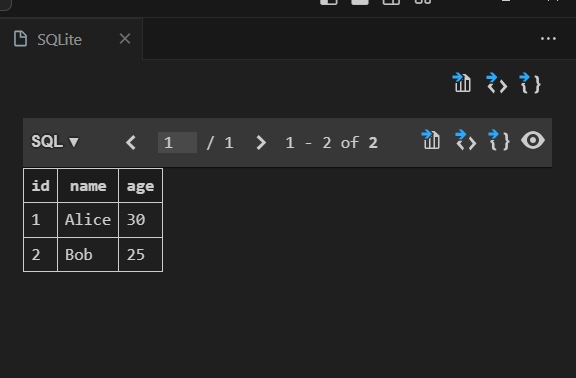
We can view the data in Visual Stude code whether data has been insert into database or not.
pip install redis
2. Starting the Redis server
redis-server
redis Python package. If not, install using:2. Connecting to SQLite & Fetching Data:
def fetch_from_sqlite(user_id):
conn = sqlite3.connect('example.db')
cursor = conn.cursor()
cursor.execute("SELECT name FROM users WHERE id=?", (user_id,))
user_name = cursor.fetchone()
conn.close()
return user_name
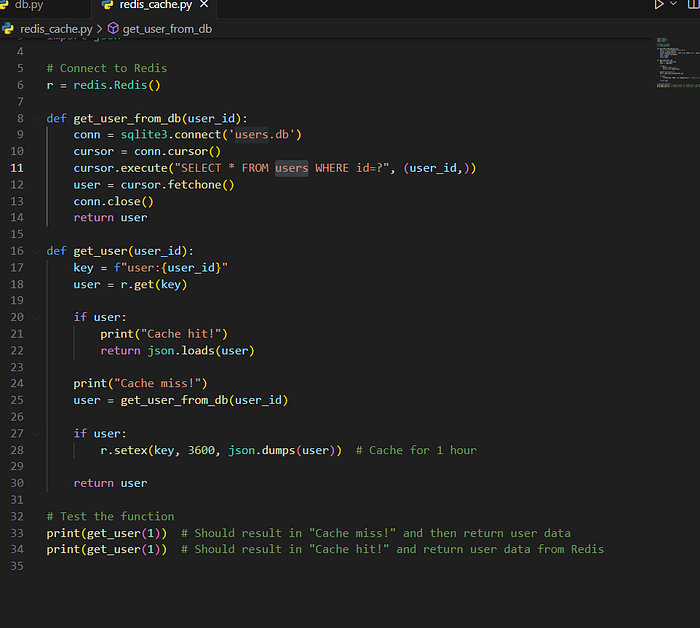
3. Redis-Python Integration & Caching:
import redis
import sqlite3
import json
# Connect to Redis
r = redis.Redis()
def get_user_from_db(user_id):
conn = sqlite3.connect('users.db')
cursor = conn.cursor()
cursor.execute("SELECT * FROM users WHERE id=?", (user_id,))
user = cursor.fetchone()
conn.close()
return user
def get_user(user_id):
key = f"user:{user_id}"
user = r.get(key)
if user:
print("Cache hit!")
return json.loads(user)
print("Cache miss!")
user = get_user_from_db(user_id)
if user:
r.setex(key, 3600, json.dumps(user)) # Cache for 1 hour
return user
# Test the function
print(get_user(1)) # Should result in "Cache miss!" and then return user data
print(get_user(1)) # Should result in "Cache hit!" and return user data from Redis
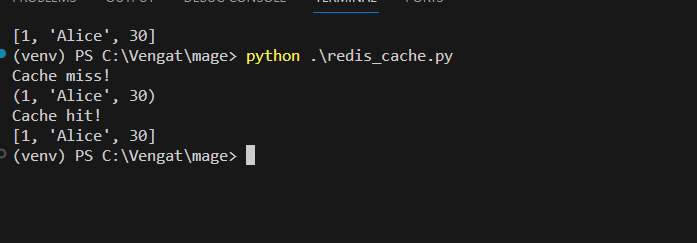
As you see the above screenshot, first time, when its hit its from DB then second call its from Redis. In order to make sure its coming from Redis only or not. We can connect to redis client and validate the same.
To check the data in your Redis using the Redis CLI:
Access the terminal or command prompt on your system.
2. Connect to Redis:
If Redis is running on the default port on your local machine, simply type:
redis-cli
3. Retrieve Data:
You can retrieve the data using Redis commands. For instance, if you set the data using a key like “user:1”, you can retrieve it with:
get user:1
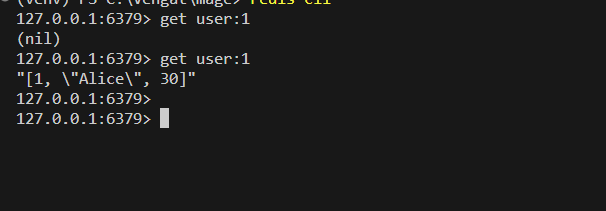
Cool :) Now we can ensure the data is coming from redis only.
This integration allows us to enjoy the best of both worlds: the persistency of SQLite and the speed of Redis. Whether you’re building web applications, analytical tools, or data-driven services, this stack ensures your data layer is both fast and reliable.
If you found this article insightful and wish to delve deeper into full-stack development or data engineering projects, I’d be thrilled to guide and collaborate further. Feel free to reach out through the mentioned channels below, and let’s make technology work for your unique needs.
Contact Channels:
Thank you for embarking on this journey with me through the realms of real-time data processing. Looking forward to our future collaborations.
0 reactions









