Join the Teckiy Community
Sign up for Free !!
World's first open source developer community with
Ticketing System

 0 reactions
0 reactions
Optimizing Apache Spark queries can lead to significant improvements in performance and resource utilization. Below are some general tips and strategies for speeding up your Spark queries based on my experience,
Pre- requisite
I have used Codelab Notebook for executing the Spark code,
Partitioning divides your dataset into smaller parts based on a specified column or set of columns, which helps in distributing the data more efficiently across the nodes.
Let’s design an example using a e-commerce scenario. Suppose we have three DataFrames: orders, products, and customers. We will focus on the partitioning of the orders DataFrame for this example.
First, let’s create some sample data:
from pyspark.sql import SparkSession
from pyspark.sql import Row
spark = SparkSession.builder.appName("PartitioningExample").getOrCreate()
# Sample data for customers, products, and orders
customers_list = [Row(id=1, name="Vengat"), Row(id=2, name="Varnika"), Row(id=3, name="magi")]
products_list = [Row(id=1, name="Laptop"), Row(id=2, name="Phone"), Row(id=3, name="Tablet")]
orders_list = [Row(id=1, customerId=1, productId=2), Row(id=2, customerId=2, productId=3), Row(id=3, customerId=3, productId=1), Row(id=4, customerId=1, productId=1)]
customers = spark.createDataFrame(customers_list)
products = spark.createDataFrame(products_list)
orders = spark.createDataFrame(orders_list)

Lets take we want to repartition the orders DataFrame based on customerId: We have partitioned based on number of distinct count customer values in Customer table(DF)
# Repartition based on 'customerId' orders_repartitioned = orders.repartition(3, "customerId") print(orders_repartitioned.rdd.getNumPartitions()) # To check the number of partitions
If you want to save the repartitioned data to a persistent storage like HDFS or S3, you can partition it by customerId:
This will create separate directories (partitions) for each unique customerId in the destination path.

When joining orders and customers, if both DataFrames are partitioned by customerId, Spark can perform optimizations like avoiding shuffles:
customers_repartitioned = customers.repartition("id")
joined = orders_repartitioned.join(customers_repartitioned, orders_repartitioned.customerId == customers_repartitioned.id)
If you find that your DataFrame is over-partitioned (too many small partitions), you can use coalesce to reduce the number of partitions:
coalesced_orders = orders_repartitioned.coalesce(2) print(coalesced_orders.rdd.getNumPartitions())
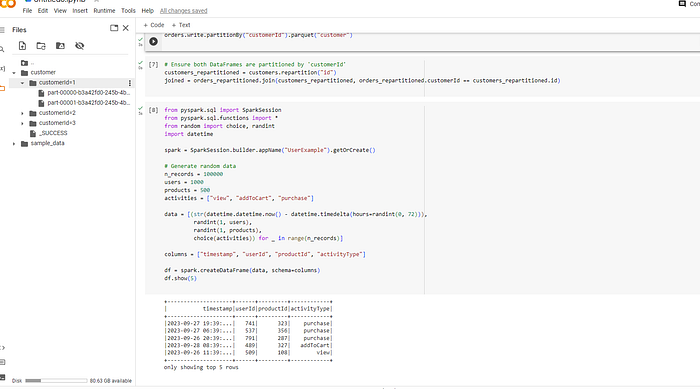
Lets take another example to understand more about data partitioning. Our sample example using a e-commerce dataset, where we have records of user activity on an online platform. This dataset contains user interactions like views, adds to cart, and purchases.
Suppose our dataset has the following columns:
timestamp: the time of the activityuserId: unique identifier for usersproductId: unique identifier for productsactivityType: type of activity, e.g., 'view', 'addToCart', 'purchase'
from pyspark.sql import SparkSession
from pyspark.sql.functions import *
from random import choice, randint
import datetime
spark = SparkSession.builder.appName("UserExample").getOrCreate()
# Generate random data
n_records = 100000
users = 1000
products = 500
activities = ["view", "addToCart", "purchase"]
data = [(str(datetime.datetime.now() - datetime.timedelta(hours=randint(0, 72))),
randint(1, users),
randint(1, products),
choice(activities)) for _ in range(n_records)]
columns = ["timestamp", "userId", "productId", "activityType"]
df = spark.createDataFrame(data, schema=columns)
df.show(5)
activityType: Let's say you frequently query data based on the type of activity. Partitioning by activityType can optimize your queries.
df_activity_partitioned = df.repartition("activityType")
2. By timestamp: If you often perform time-based analysis, partitioning by a time column is beneficial. However, our timestamp has a high cardinality, making it suboptimal for direct partitioning. Instead, we can create a date column and partition by it.
df_with_date = df.withColumn("date", to_date(col("timestamp")))
df_date_partitioned = df_with_date.repartition("date")
After repartitioning, you can write the data to storage, like HDFS or S3, in a partitioned manner:
# Writing activity partitioned
datadf_activity_partitioned.write.partitionBy("activityType").parquet("customer_actvity")
# Writing date partitioned
datadf_date_partitioned.write.partitionBy("date").parquet("customer_date")
I hope you found this guide helpful. Your feedback fuels my passion for sharing knowledge, so if you appreciated this article, please give it a thumbs up and share your thoughts in the comments below.
For more insights and to stay connected, you can find me on:
0 reactions









