Join the Teckiy Community
Sign up for Free !!
World's first open source developer community with
Ticketing System
 0 reactions
0 reactions
What is multiprocessing?
Multiprocessing refers to the ability of a system to support more than one processor at the same time. Applications in a multiprocessing system are broken to smaller routines that run independently. The operating system allocates these threads to the processors improving performance of the system.
Why multiprocessing?
Consider a computer system with a single processor. If it is assigned several processes at the same time, it will have to interrupt each task and switch briefly to another, to keep all of the processes going.
This situation is just like a chef working in a kitchen alone. He has to do several tasks like baking, stirring, kneading dough, etc.
So the gist is that: The more tasks you must do at once, the more difficult it gets to keep track of them all, and keeping the timing right becomes more of a challenge.
This is where the concept of multiprocessing arises!
A multiprocessing system can have:
Here, the CPU can easily executes several tasks at once, with each task using its own processor.
It is just like the chef in last situation being assisted by his assistants. Now, they can divide the tasks among themselves and chef doesn’t need to switch between his tasks.
Now let us get our hands on the multiprocessing library in Python.
Take a look at the following code
import time
def sleepy_man():
print('Starting to sleep')
time.sleep(1)
print('Done sleeping')
tic = time.time()
sleepy_man()
sleepy_man()
toc = time.time()
print('Done in {:.4f} seconds'.format(toc-tic))
In the era of Big Data, Python has become the most sought-after language. In this article, let us concentrate on one particular aspect of Python that makes it one of the most powerful Programming languages- Multi-Processing.
Let us say you are an elementary school student who is given the mind-numbing task of multiplying 1200 pairs of numbers as your homework. Let us say you are capable of multiplying a pair of numbers within 3 seconds. Then on a total, it takes 1200*3 = 3600 seconds, which is 1 hour to solve the entire assignment. But you have to catch up on your favorite TV show in 20 minutes.
What would you do? An intelligent student, though dishonest, will call up three more friends who have similar capacity and divide the assignment. So you’ll get 250 multiplications tasks on your plate, which you’ll complete in 250*3 = 750 seconds, that is 15 minutes. Thus, you along with your 3 other friends, will finish the task in 15 minutes, giving you 5 minutes time to grab a snack and sit for your TV show. The task just took 15 minutes when 4 of you work together, which otherwise would have taken 1 hour.
This is the basic ideology of Multi-Processing. If you have an algorithm that can be divided into different workers(processors), then you can speed up the program. Machines nowadays come with 4,8 and 16 cores, which then can be deployed in parallel.
Multi-Processing has two crucial applications in Data Science.
Any data-intensive pipeline has input, output processes where millions of bytes of data flow throughout the system. Generally, the data reading(input) process won’t take much time but the process of writing data to Data Warehouses takes significant time. The writing process can be made in parallel, saving a huge amount of time.

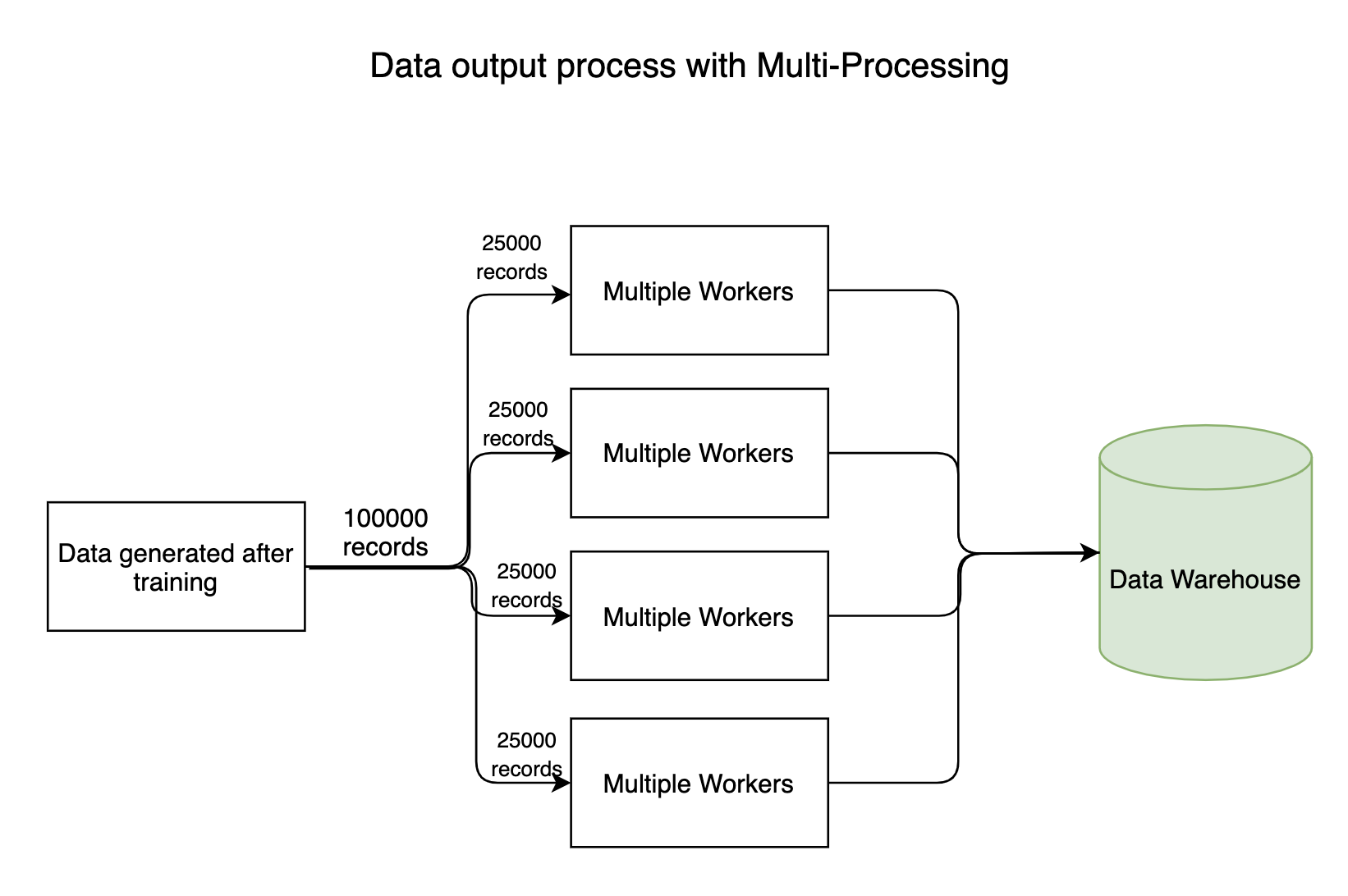
Though not all models can be trained in parallel, few models have inherent characteristics that allow them to get trained using parallel processing. For example, the Random Forest algorithm deploys multiple Decision trees to take a cumulative decision. These trees can be constructed in parallel. In fact, the sklearn API comes with a parameter called n_jobs, which provides an option to use multiple workers.
Now let us get our hands on the multiprocessing library in Python.
Take a look at the following code
import time
def sleepy_man():
print('Starting to sleep')
time.sleep(1)
print('Done sleeping')
tic = time.time()
sleepy_man()
sleepy_man()
toc = time.time()
print('Done in {:.4f} seconds'.format(toc-tic))
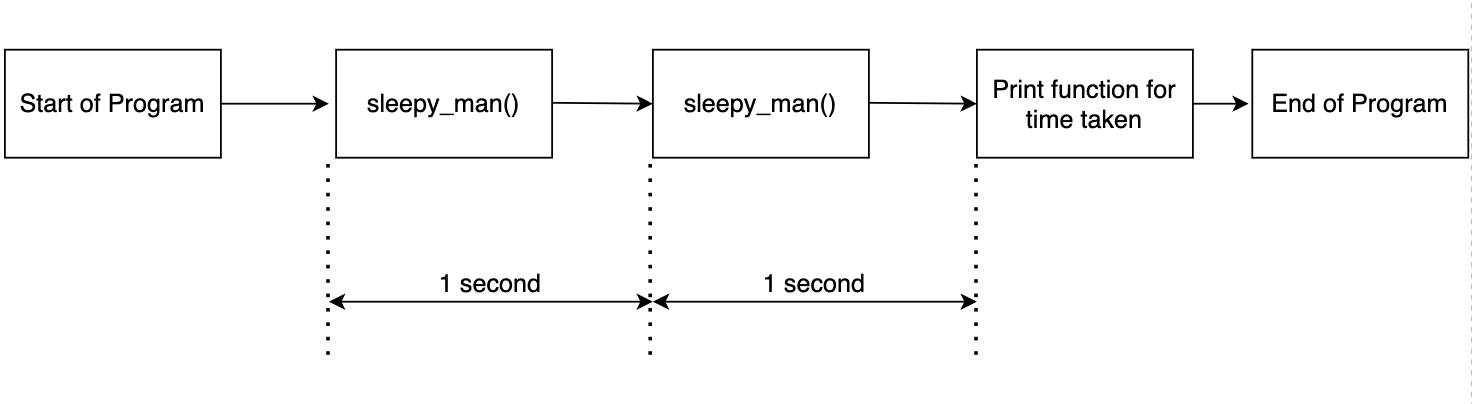
The above code is simple. The function sleepy_man sleeps for a second and we call the function two times. We record the time taken for the two function calls and print the results. The output is as shown below.
Starting to sleep Done sleeping Starting to sleep Done sleeping Done in 2.0037 seconds
This is expected as we call the function twice and record the time. The flow is shown in the diagram below.
Let us say you are an elementary school student who is given the mind-numbing task of multiplying 1200 pairs of numbers as your homework. Let us say you are capable of multiplying a pair of numbers within 3 seconds. Then on a total, it takes 1200*3 = 3600 seconds, which is 1 hour to solve the entire assignment. But you have to catch up on your favorite TV show in 20 minutes.
What would you do? An intelligent student, though dishonest, will call up three more friends who have similar capacity and divide the assignment. So you’ll get 250 multiplications tasks on your plate, which you’ll complete in 250*3 = 750 seconds, that is 15 minutes. Thus, you along with your 3 other friends, will finish the task in 15 minutes, giving you 5 minutes time to grab a snack and sit for your TV show. The task just took 15 minutes when 4 of you work together, which otherwise would have taken 1 hour.
This is the basic ideology of Multi-Processing. If you have an algorithm that can be divided into different workers(processors), then you can speed up the program. Machines nowadays come with 4,8 and 16 cores, which then can be deployed in parallel.
Multi-Processing has two crucial applications in Data Science.
Any data-intensive pipeline has input, output processes where millions of bytes of data flow throughout the system. Generally, the data reading(input) process won’t take much time but the process of writing data to Data Warehouses takes significant time. The writing process can be made in parallel, saving a huge amount of time.
Though not all models can be trained in parallel, few models have inherent characteristics that allow them to get trained using parallel processing. For example, the Random Forest algorithm deploys multiple Decision trees to take a cumulative decision. These trees can be constructed in parallel. In fact, the sklearn API comes with a parameter called n_jobs, which provides an option to use multiple workers.
Now let us get our hands on the multiprocessing library in Python.
Take a look at the following code
import time
def sleepy_man():
print('Starting to sleep')
time.sleep(1)
print('Done sleeping')
tic = time.time()
sleepy_man()
sleepy_man()
toc = time.time()
print('Done in {:.4f} seconds'.format(toc-tic))
The above code is simple. The function sleepy_man sleeps for a second and we call the function two times. We record the time taken for the two function calls and print the results. The output is as shown below.
Starting to sleep Done sleeping Starting to sleep Done sleeping Done in 2.0037 seconds
This is expected as we call the function twice and record the time. The flow is shown in the diagram below.
Now let us incorporate Multi-Processing into the code.
import multiprocessing import time
def sleepy_man():
print('Starting to sleep')
time.sleep(1)
print('Done sleeping')
tic = time.time()
p1 = multiprocessing.Process(target= sleepy_man)
p2 = multiprocessing.Process(target= sleepy_man)
p1.start()
p2.start()
toc = time.time()
print('Done in {:.4f} seconds'.format(toc-tic))
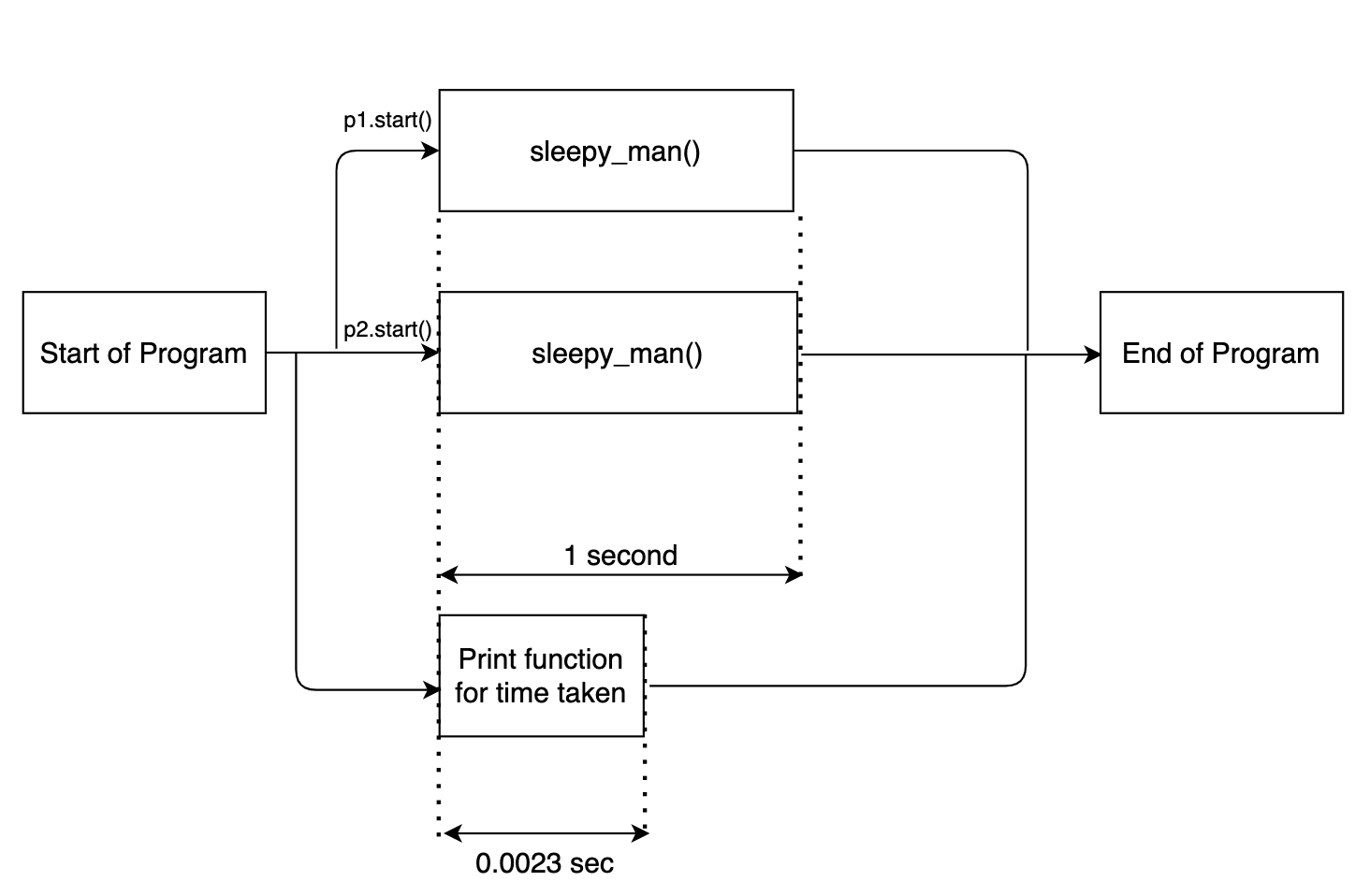
Here multiprocessing.Process(target= sleepy_man) defines a multi-process instance. We pass the required function to be executed, sleepy_man, as an argument. We trigger the two instances by p1.start().
The output is as follows-
Done in 0.0023 seconds Starting to sleep Starting to sleep Done sleeping Done sleeping
Now notice one thing. The time log print statement got executed first. This is because along with the multi-process instances triggered for the sleepy_man function, the main code of the function got executed separately in parallel. The flow diagram given below will make things clear.
In order to execute the rest of the program after the multi-process functions are executed, we need to execute the function join().
import multiprocessing
import time
def sleepy_man():
print('Starting to sleep')
time.sleep(1)
print('Done sleeping')
tic = time.time()
p1 = multiprocessing.Process(target= sleepy_man)
p2 = multiprocessing.Process(target= sleepy_man)
p1.start()
p2.start()
p1.join()
p2.join()
toc = time.time()
print('Done in {:.4f} seconds'.format(toc-tic))
Now the rest of the code block will only get executed after the multiprocessing tasks are done. The output is shown below.
Starting to sleep Starting to sleep Done sleeping Done sleeping Done in 1.0090 seconds
The flow diagram is shown below.
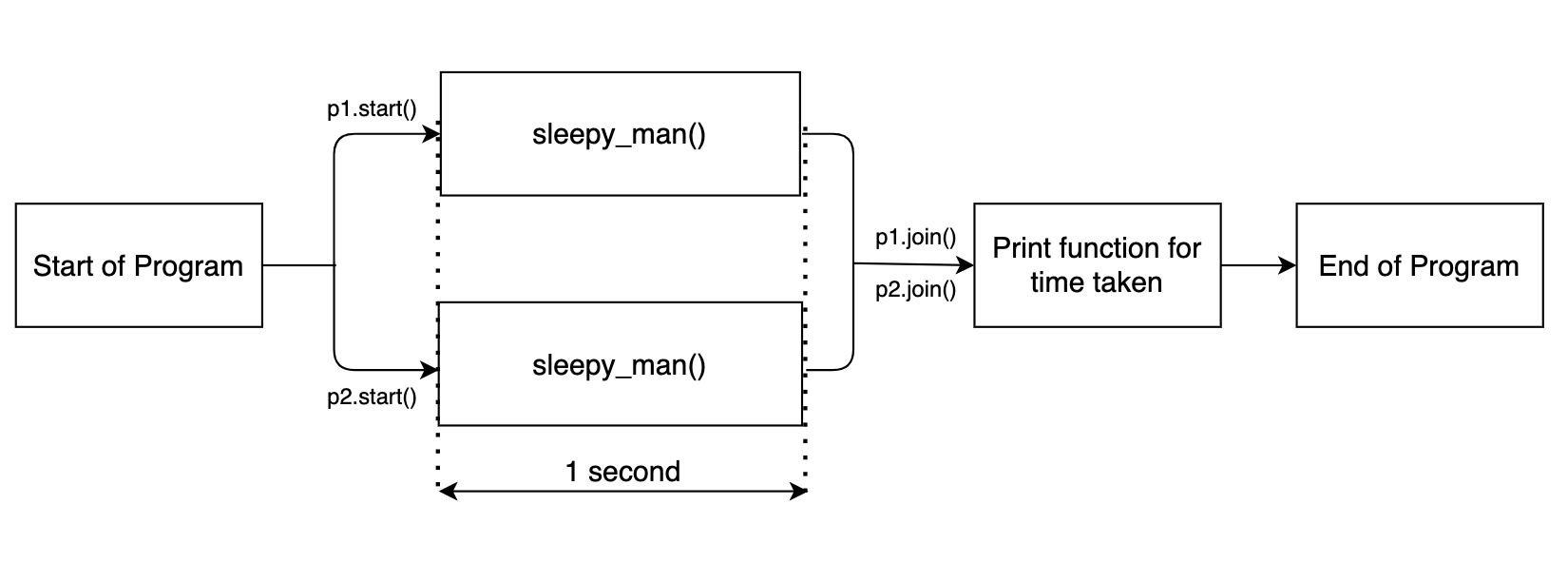
Since the two sleep functions are executed in parallel, the function together takes around 1 second.
We can define any number of multi-processing instances. Look at the code below. It defines 10 different multi-processing instances using a for a loop.
import multiprocessing
import time
def sleepy_man():
print('Starting to sleep')
time.sleep(1)
print('Done sleeping')
tic = time.time()
process_list = []
for i in range(10):
p = multiprocessing.Process(target= sleepy_man)
p.start()
process_list.append(p)
for process in process_list:
process.join()
toc = time.time()
print('Done in {:.4f} seconds'.format(toc-tic))
The output for the above code is as shown below.
Starting to sleep Starting to sleep Starting to sleep Starting to sleep Starting to sleep Starting to sleep Starting to sleep Starting to sleep Starting to sleep Starting to sleep Done sleeping Done sleeping Done sleeping Done sleeping Done sleeping Done sleeping Done sleeping Done sleeping Done sleeping Done sleeping Done in 1.0117 seconds
Here the ten function executions are processed in parallel and thus the entire program takes just one second. Now my machine doesn’t have 10 processors. When we define more processes than our machine, the multiprocessing library has a logic to schedule the jobs. So you don’t have to worry about it.
We can also pass arguments to the Process function using args.
import multiprocessing
import time
def sleepy_man(sec):
print('Starting to sleep')
time.sleep(sec)
print('Done sleeping')
tic = time.time()
process_list = []
for i in range(10):
p = multiprocessing.Process(target= sleepy_man, args = [2])
p.start()
process_list.append(p)
for process in process_list:
process.join()
toc = time.time()
print('Done in {:.4f} seconds'.format(toc-tic))
The output for the above code is as shown below.
Starting to sleep Starting to sleep Starting to sleep Starting to sleep Starting to sleep Starting to sleep Starting to sleep Starting to sleep Starting to sleep Starting to sleep Done sleeping Done sleeping Done sleeping Done sleeping Done sleeping Done sleeping Done sleeping Done sleeping Done sleeping Done sleeping Done in 2.0161 seconds
Since we passed an argument, the sleepy_man function slept for 2 seconds instead of 1 second.
0 reactions









